PDF Document Loader
Overview
The PDF Document Loader is a powerful feature in AnswerAI that allows you to extract and process text content from PDF files. This tool is essential for users who need to work with information stored in PDF format, enabling easy integration of PDF content into their AnswerAI workflows.
Key Benefits
- Easily extract text content from PDF files
- Flexible options for processing PDF documents (per page or per file)
- Ability to split large documents into manageable chunks
How to Use
-
Select the PDF File
- Choose the PDF file(s) you want to process.
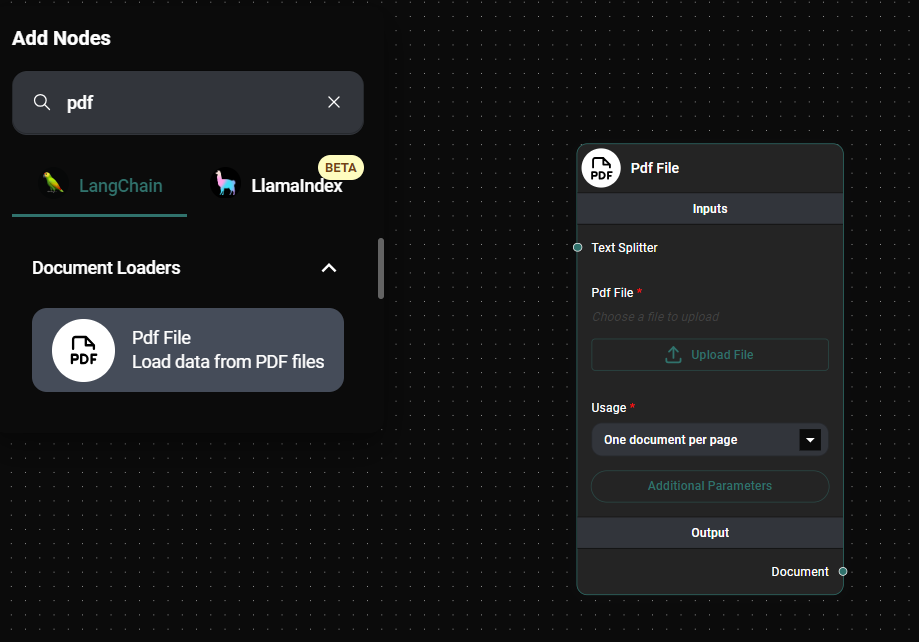
Pdf Loader File Selection Interface & Drop UI
-
Configure Text Splitter (Optional)
- If needed, select a Text Splitter to break down large documents.
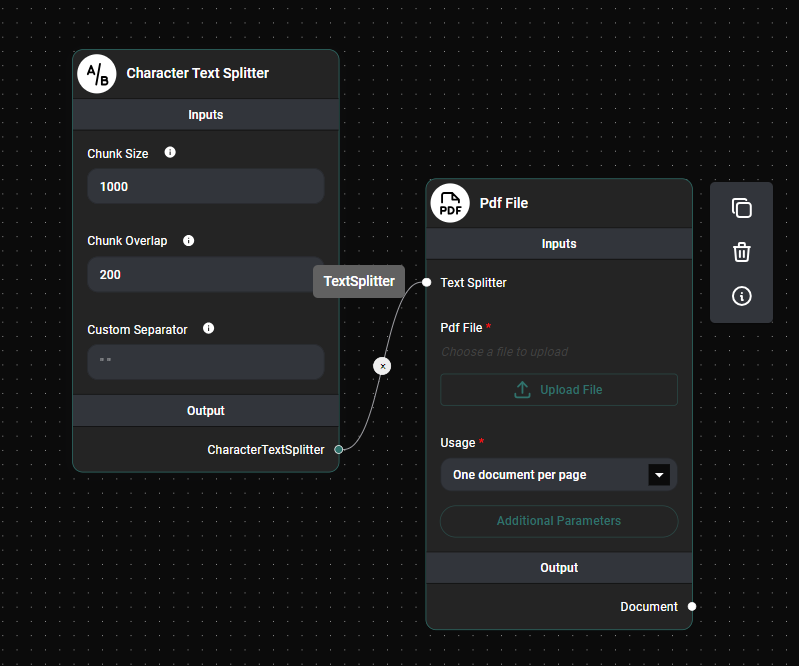
Text Splitter Node & Drop UI
- If needed, select a Text Splitter to break down large documents.
-
Choose Usage Option
- Select either "One document per page" or "One document per file" based on your needs.
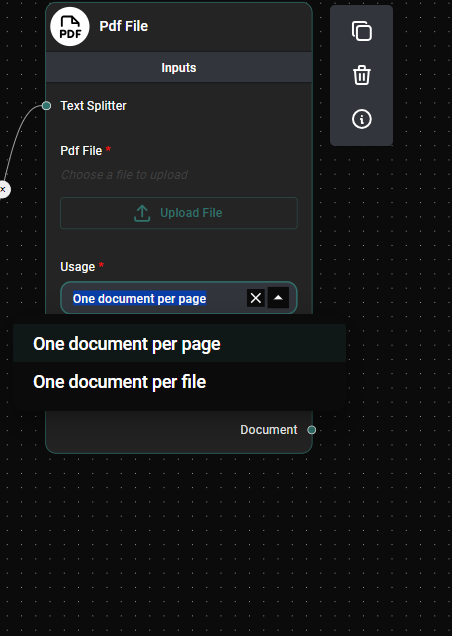
Pdf Usage & Drop UI
- Select either "One document per page" or "One document per file" based on your needs.
-
Set Additional Parameters (Optional)
- Use Legacy Build: Enable if you're working with older PDF formats.
- Additional Metadata: Add extra information to the extracted documents.
- Omit Metadata Keys: Specify which metadata keys to exclude.

Pdf Additional Parameters & Drop UI
-
Process the PDF
- Run the PDF Document Loader to extract the content.
Tips and Best Practices
- Use the Text Splitter option for large PDFs to create more manageable chunks of text.
- When working with multiple PDFs, consider using the "One document per file" option for easier organization.
- Utilize the Additional Metadata feature to add context or categorization to your extracted documents.
- If you encounter issues with older PDFs, try enabling the "Use Legacy Build" option.
Troubleshooting
-
PDF not loading properly:
- Ensure the PDF file is not corrupted or password-protected.
- Try using the "Use Legacy Build" option for older PDF formats.
-
Extracted text is jumbled or incorrectly formatted:
- This can happen with complex PDF layouts. Try adjusting the Text Splitter settings or processing the document page by page.
-
Missing metadata:
- Check the "Omit Metadata Keys" field to ensure you haven't accidentally excluded important metadata.
Note on Image Handling
Please be aware that the current version of the PDF Document Loader does not handle images within PDF files very well. Our team is actively working on improving image processing capabilities to provide a more comprehensive PDF handling experience in future updates.