Cheerio Web Scraper
Overview
The Cheerio Web Scraper is a powerful tool in AnswerAI that allows you to load and process data from web pages. It provides flexible options for scraping content, handling relative links, and customizing the extracted data.
Key Benefits
- Easily extract content from web pages using CSS selectors
- Crawl websites or scrape XML sitemaps to process multiple pages
- Customize metadata and control the amount of data extracted
How to Use
-
Add the Cheerio Web Scraper node to your AnswerAI workflow.
-
Configure the node with the following settings:
a. URL: Enter the target web page URL.
b. Text Splitter (optional): Connect a Text Splitter node to process the extracted content.
c. Get Relative Links Method (optional): Choose between "Web Crawl" or "Scrape XML Sitemap" to process multiple pages.
d. Get Relative Links Limit (optional): Set the maximum number of relative links to process (0 for unlimited).
e. Selector (CSS) (optional): Specify a CSS selector to target specific content on the page.
f. Additional Metadata (optional): Add custom metadata to the extracted documents.
g. Omit Metadata Keys (optional): Exclude specific metadata keys from the output.
-
Connect the Cheerio Web Scraper node to other nodes in your workflow to process the extracted data further.
Tips and Best Practices
- Use specific CSS selectors to target the exact content you need, reducing noise in your extracted data.
- When crawling multiple pages, start with a small limit to test your workflow before increasing the number of pages processed.
- Combine the Cheerio Web Scraper with Text Splitters and other processing nodes to create more refined document chunks.
- Utilize the Additional Metadata field to add custom information to your documents, such as source type or category.
Troubleshooting
- Invalid URL error: Ensure that the URL you've entered is correct and includes the proper protocol (http:// or https://).
- No relative links found: Check that the target website allows crawling and that the XML sitemap is accessible (if using the Scrape XML Sitemap method).
- Slow performance: When processing many pages, consider increasing the limit gradually to find the optimal balance between data quantity and processing time.
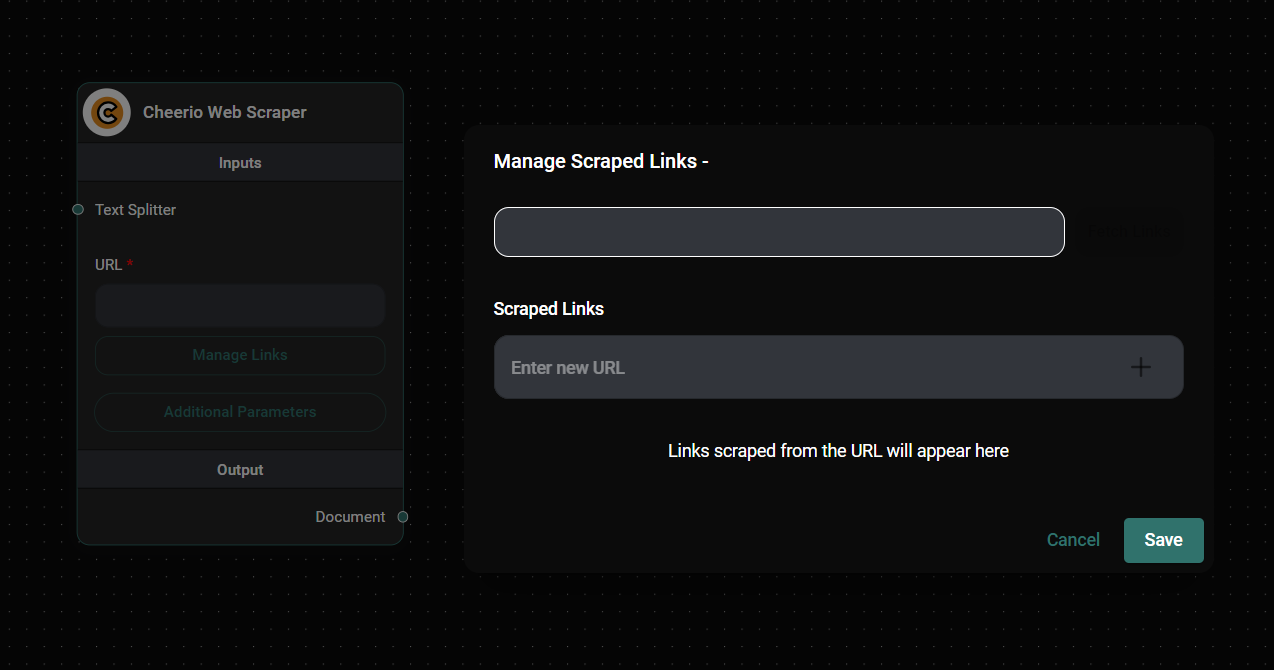
Cheerio Web Scraper Node Configuration & Drop UI
API Reference
For advanced usage, you can refer to the Cheerio Web Scraper API documentation:
class Cheerio_DocumentLoaders implements INode {
label: string
name: string
version: number
description: string
type: string
icon: string
category: string
baseClasses: string[]
inputs: INodeParams[]
constructor()
async init(nodeData: INodeData, _: string, options: ICommonObject): Promise<any>
}
The init method is the main function that processes the input and returns the extracted documents. It handles URL validation, web crawling or XML sitemap scraping, content extraction, and metadata customization.
Remember to handle errors and edge cases when integrating the Cheerio Web Scraper into your AnswerAI workflows, especially when dealing with external websites that may change or become unavailable.