Multiple Documents QnA
From the last Web Scrape QnA example, we are only upserting and querying 1 website. What if we have multiple websites, or multiple documents? Let's take a look and see how we can achieve that.
In this example, we are going to perform QnA on 2 PDFs, which are FORM-10K of APPLE and TESLA.
.png)
.png)
Upsert
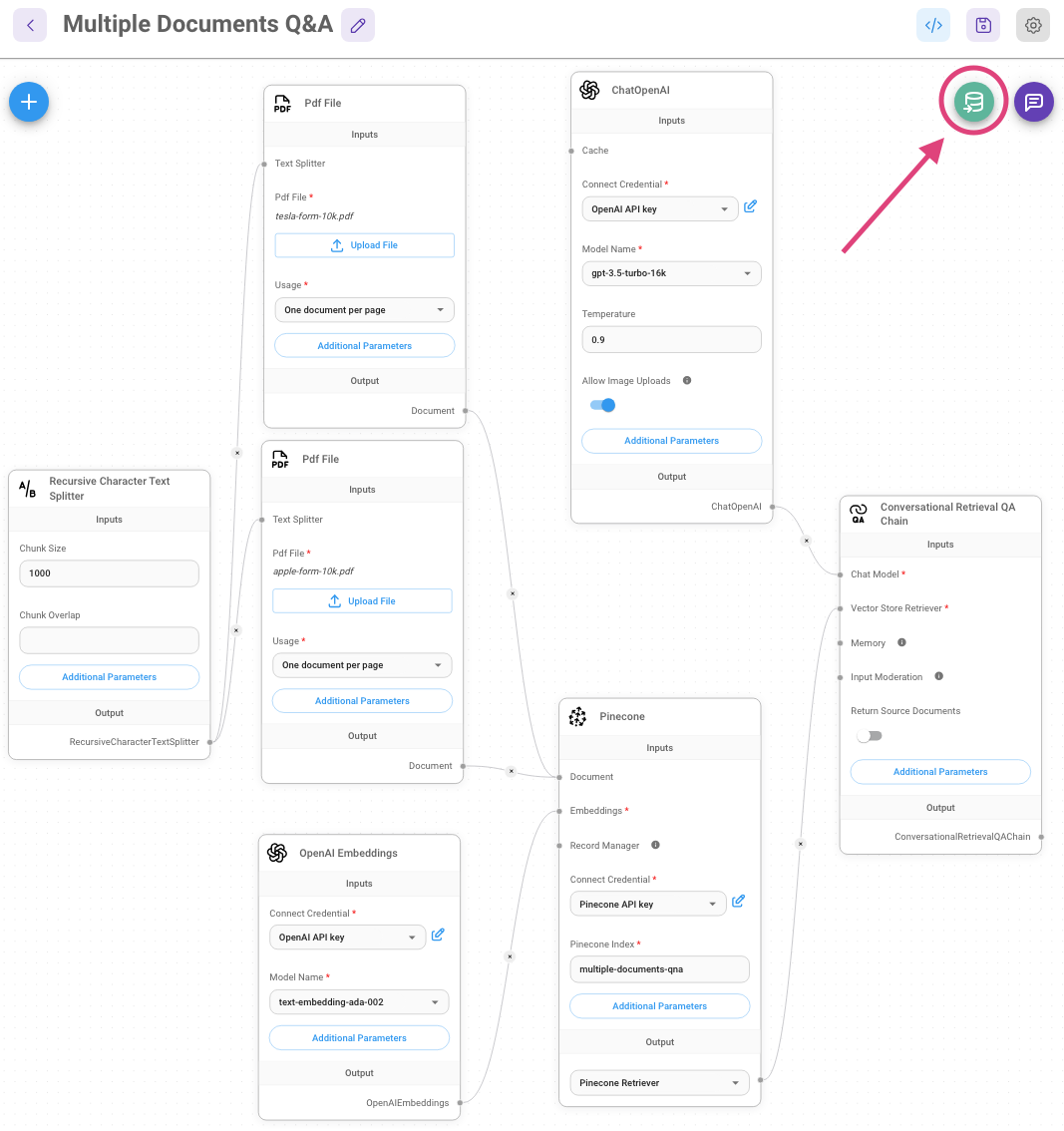
- Find the example flow called - Conversational Retrieval QA Chain from the marketplace templates.
- We are going to use PDF File Loader, and upload the respective files:
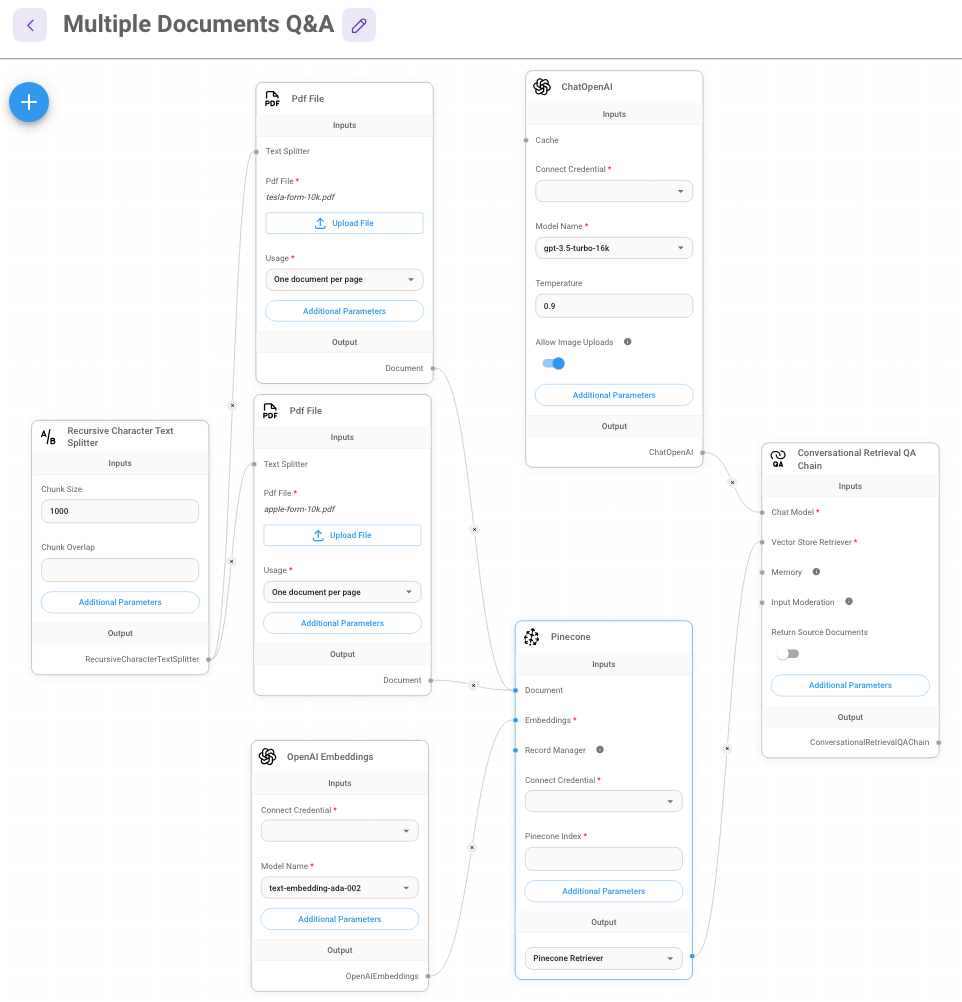
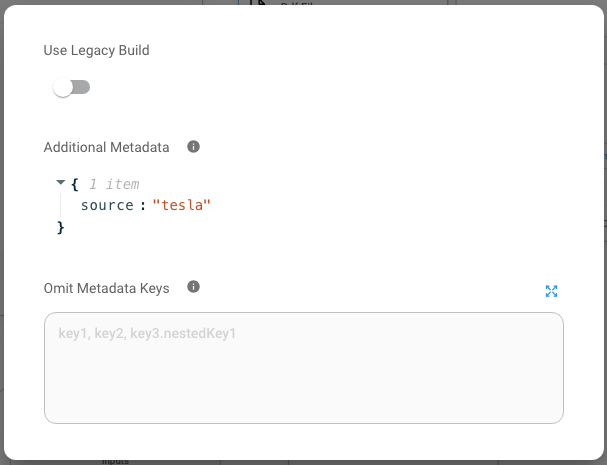
- Click the Additional Parameters of PDF File Loader, and specify metadata object. For instance, PDF File with Apple FORM-10K uploaded can have a metadata object
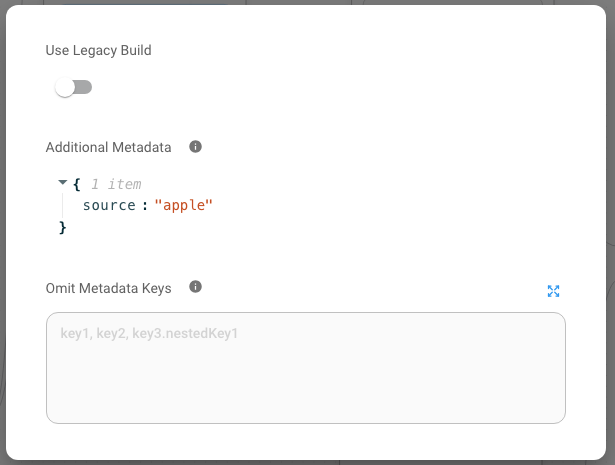
{source: apple}, whereas PDF File with Tesla FORM-10K uploaded can have{source: tesla}. This is done to seggregate the documents during retrieval time.
- After filling in the credentials for Pinecone, click Upsert:
.png)
- On the Pinecone console you will be able to see the new vectors that were added.
Query
- After verifying data has been upserted to Pinecone, we can now start asking question in the chat!
.png)
- However, the context retrieved used to return the answer is a mix of both APPLE and TESLA documents. As you can see from the Source Documents:
.png)
.png)
- We can fix this by specifying a metadata filter from the Pinecone node. For example, if we only want to retrieve context from APPLE FORM-10K, we can look back at the metadata we have specified earlier in the #upsert step, then use the same in the Metadata Filter below:
.png)
- Let's ask the same question again, we should now see all context retrieved are indeed from APPLE FORM-10K:
.png)
Each vector databse provider has different format of filtering syntax, recommend to read through the respective vector database documentation
- However, the problem with this is that metadata filtering is sort of "hard-coded". Ideally, we should let the LLM to decide which document to retrieve based on the question.
Tool Agent
We can solve the "hard-coded" metadata filter problem by using Tool Agent.
By providing tools to agent, we can let the agent to decide which tool is suitable to be used depending on the question.
- Create a Retriever Tool with following name and description:
| Name | Description |
|---|---|
| search_apple | Use this function to answer user questions about Apple Inc (APPL). It contains a SEC Form 10K filing describing the financials of Apple Inc (APPL) for the 2022 time period. |
- Connect to Pinecone node with metadata filter
{source: apple}
.png)
- Repeat the same for Tesla:
| Name | Description | Pinecone Metadata Filter |
|---|---|---|
| search_tsla | Use this function to answer user questions about Tesla Inc (TSLA). It contains a SEC Form 10K filing describing the financials of Tesla Inc (TSLA) for the 2022 time period. | |
It is important to specify a clear and concise description. This allows LLM to better decide when to use which tool
Your flow should looks like below:
.png)
- Now, we need to create a general instruction to Tool Agent. Click Additional Parameters of the node, and specify the System Message. For example:
You are an expert financial analyst that always answers questions with the most relevant information using the tools at your disposal.
These tools have information regarding companies that the user has expressed interest in.
Here are some guidelines that you must follow:
* For financial questions, you must use the tools to find the answer and then write a response.
* Even if it seems like your tools won't be able to answer the question, you must still use them to find the most relevant information and insights. Not using them will appear as if you are not doing your job.
* You may assume that the users financial questions are related to the documents they've selected.
* For any user message that isn't related to financial analysis, respectfully decline to respond and suggest that the user ask a relevant question.
* If your tools are unable to find an answer, you should say that you haven't found an answer but still relay any useful information the tools found.
* Dont ask clarifying questions, just return answer.
The tools at your disposal have access to the following SEC documents that the user has selected to discuss with you:
- Apple Inc (APPL) FORM 10K 2022
- Tesla Inc (TSLA) FORM 10K 2022
The current date is: 2024-01-28
- Save the Chatflow, and start asking question!
.png)
.png)
.png)
- Follow up with Tesla:
.png)
- We are now able to ask questions about any documents that we've previously upserted to vector database without "hard-coding" the metadata filtering by using tools + agent.
XML Agent
For some LLMs, function callings capabilities are not supported. In this case, we can use XML Agent to prompt the LLM in a more structured format/syntax, with the goal of using the provided tools.
It has the underlying prompt:
You are a helpful assistant. Help the user answer any questions.
You have access to the following tools:
{tools}
In order to use a tool, you can use <tool></tool> and <tool_input></tool_input> tags. You will then get back a response in the form <observation></observation>
For example, if you have a tool called 'search' that could run a google search, in order to search for the weather in SF you would respond:
<tool>search</tool><tool_input>weather in SF</tool_input>
<observation>64 degrees</observation>
When you are done, respond with a final answer between <final_answer></final_answer>. For example:
<final_answer>The weather in SF is 64 degrees</final_answer>
Begin!
Previous Conversation:
{chat_history}
Question: {input}
{agent_scratchpad}
.png)
Conclusion
We've covered using Conversational Retrieval QA Chain and its limitation when querying multiple documents. And we were able to overcome the issue by using OpenAI Function Agent/XML Agent + Tools. You can find the templates below:
Download ToolAgent Chatflow.json Download XMLAgent Chatflow.json