HyDE Retriever
Overview
The HyDE (Hypothetical Document Embeddings) Retriever is a powerful tool in AnswerAI that enhances document retrieval from a vector store. It uses a language model to generate a hypothetical answer to a query, which is then used to find relevant documents. This approach can significantly improve the quality and relevance of retrieved documents, especially for complex or nuanced queries.
Key Benefits
- Improved retrieval quality for complex queries
- Leverages the power of language models to enhance search
- Flexible configuration options for various use cases
How to Use
- Add the HyDE Retriever node to your AnswerAI canvas.
- Connect a Language Model node to the "Language Model" input.
- Connect a Vector Store node to the "Vector Store" input.
- (Optional) Provide a specific query in the "Query" field. If left empty, the user's question will be used.
- Choose a predefined prompt or create a custom one:
- Select a prompt from the "Select Defined Prompt" dropdown, or
- Enter a custom prompt in the "Custom Prompt" field (this will override the selected predefined prompt).
- (Optional) Adjust the "Top K" value to set the number of results to retrieve (default is 4).
- Choose the desired output type:
- HyDE Retriever: Returns the retriever object for further processing
- Document: Returns an array of retrieved documents
- Text: Returns a concatenated string of the retrieved documents' content
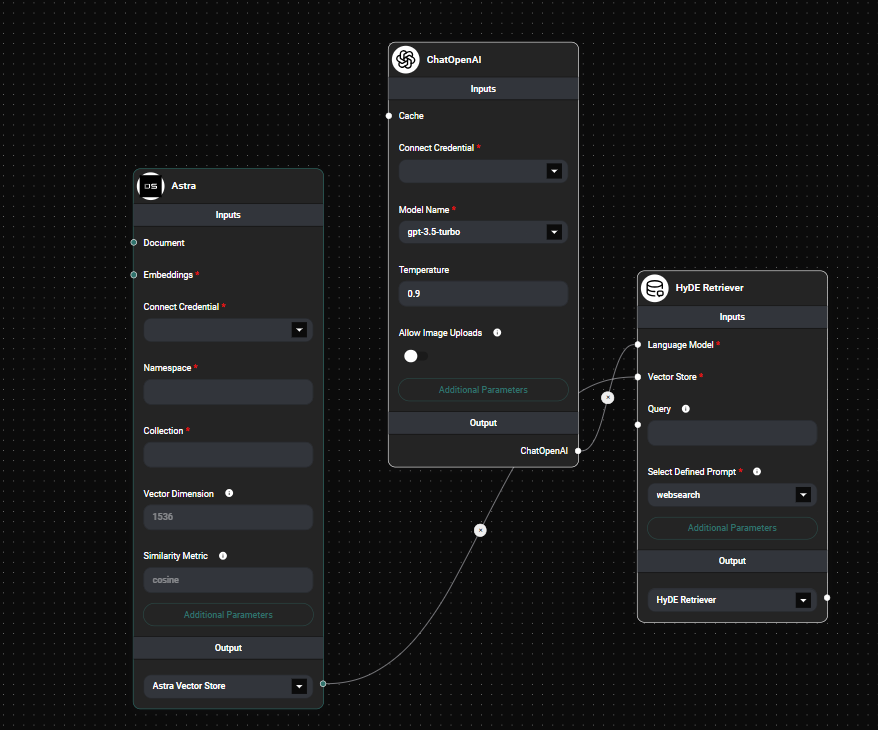
Hyde Retreiver Node & Drop UI
Tips and Best Practices
- Experiment with different prompts to find the best one for your use case. The predefined prompts cover various scenarios, but a custom prompt might work better for specific domains.
- Adjust the "Top K" value based on your needs. A higher value will return more results but may include less relevant documents.
- Use the "Document" output when you need to access individual document metadata or want to process documents separately.
- Use the "Text" output when you need a simple concatenated string of all retrieved content.
Troubleshooting
-
If the retriever is not returning expected results, try the following:
- Check if the Language Model and Vector Store are properly connected and configured.
- Experiment with different prompts or adjust the existing one.
- Increase the "Top K" value to retrieve more documents.
- Verify that the vector store contains relevant documents for your queries.
-
If you encounter performance issues:
- Reduce the "Top K" value to retrieve fewer documents.
- Use a smaller or more efficient Language Model.
- Optimize your Vector Store for faster retrieval.