Document Stores
Flowise's Document Stores offer a versatile approach to data management, enabling you to upload, split, and prepare your data for upserting your datasets in a single location.
This centralized approach simplifies data handling and allows for efficient management of various data formats, making it easier to organize and access your data within the Flowise app.
Setup
In this tutorial, we will set up a Retrieval Augmented Generation (RAG) system to retrieve information about the LibertyGuard Deluxe Homeowners Policy, a topic that LLMs are likely not extensively trained on.
Using the Flowise Document Stores, we'll prepare and upsert data about LibertyGuard and its set of home insurance policies. This will enable our RAG system to accurately answer user queries about LibertyGuard's home insurance offerings.
1. Add a Document Store
- Start by adding a Document Store and naming it. In our case, "LibertyGuard Deluxe Homeowners Policy".
2. Select a Document Loader
- Enter the Document Store we just created and select the Document Loader you want to use. In our case, since our dataset is in PDF format, we'll use the PDF Loader.


3. Preparing your data
- First, we start by uploading our PDF file.
- Then, we add a unique metadata key. This is optional, but a good practice as it allows us to target and filter down this same dataset later on if we need to.
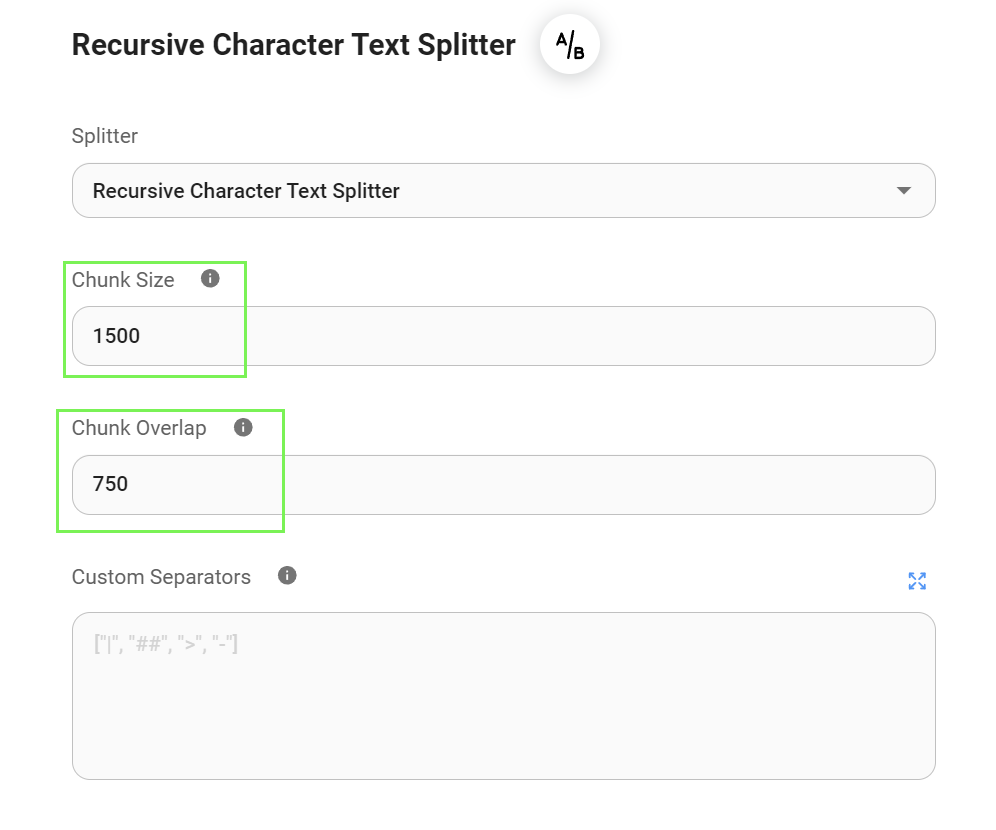
- Finally, select the Text Splitter you want to use to chunk your data. In our particular case, we will use the Recursive Character Text Splitter.
In this guide, we've added a generous Chunk Overlap size to ensure no relevant data gets missed between chunks. However, the optimal overlap size is dependent on the complexity of your data. You may need to adjust this value based on your specific dataset and the nature of the information you want to extract.
4. Preview your data
- We can now preview how our data will be chunked using our current Text Splitter configuration;
chunk_size=1500andchunk_overlap=750.
- It's important to experiment with different Text Splitters, Chunk Sizes, and Overlap values to find the optimal configuration for your specific dataset. This preview allows you to refine the chunking process and ensure that the resulting chunks are suitable for your RAG system.
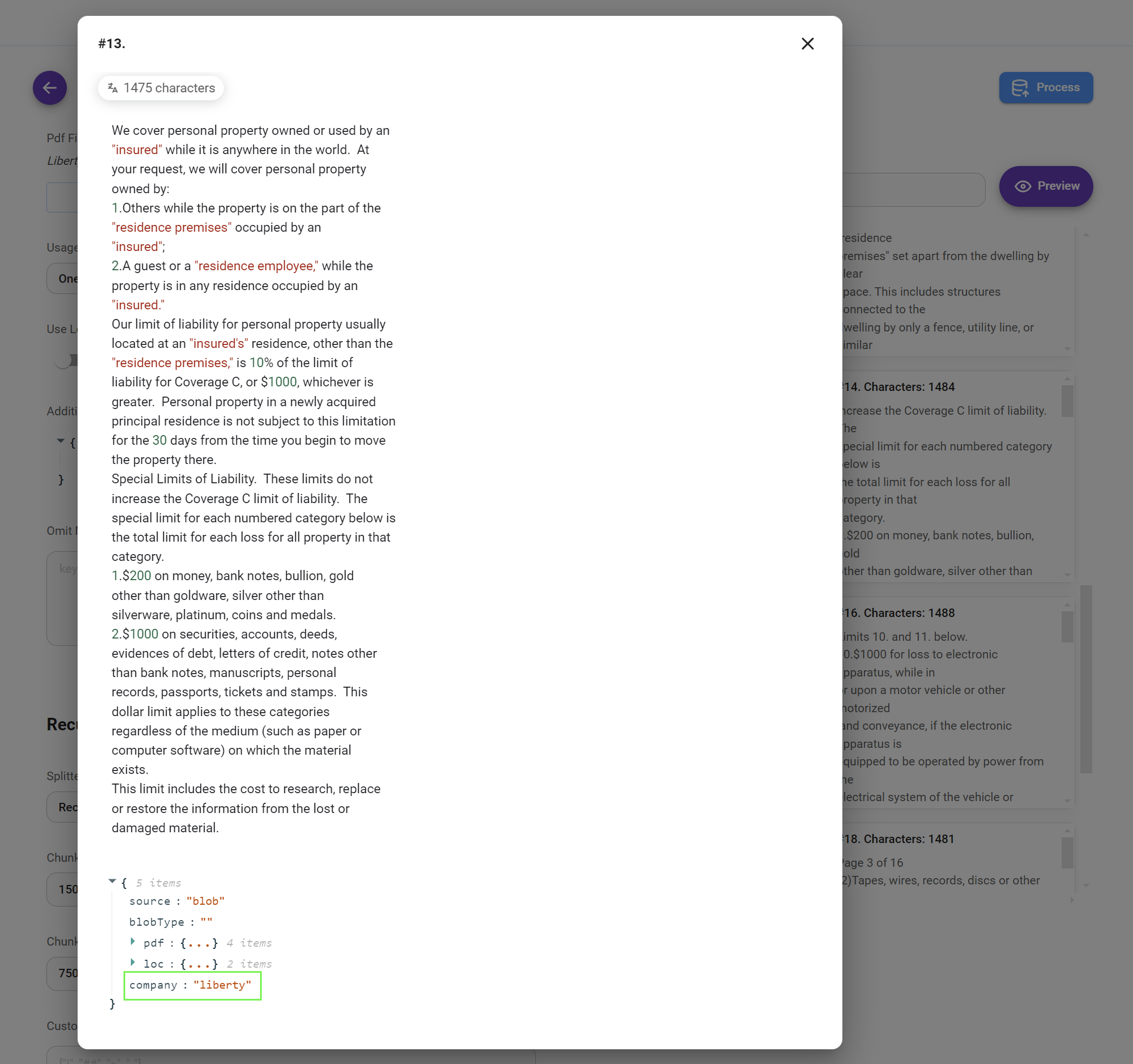
Note that our custom metadata company: "liberty" has been inserted into each chunk. This metadata allows us to easily filter and retrieve information from this specific dataset later on, even if we use the same vector store index for other datasets.
5. Process your data
- Once you are satisfied with the chunking process, it's time to process your data.
.png)
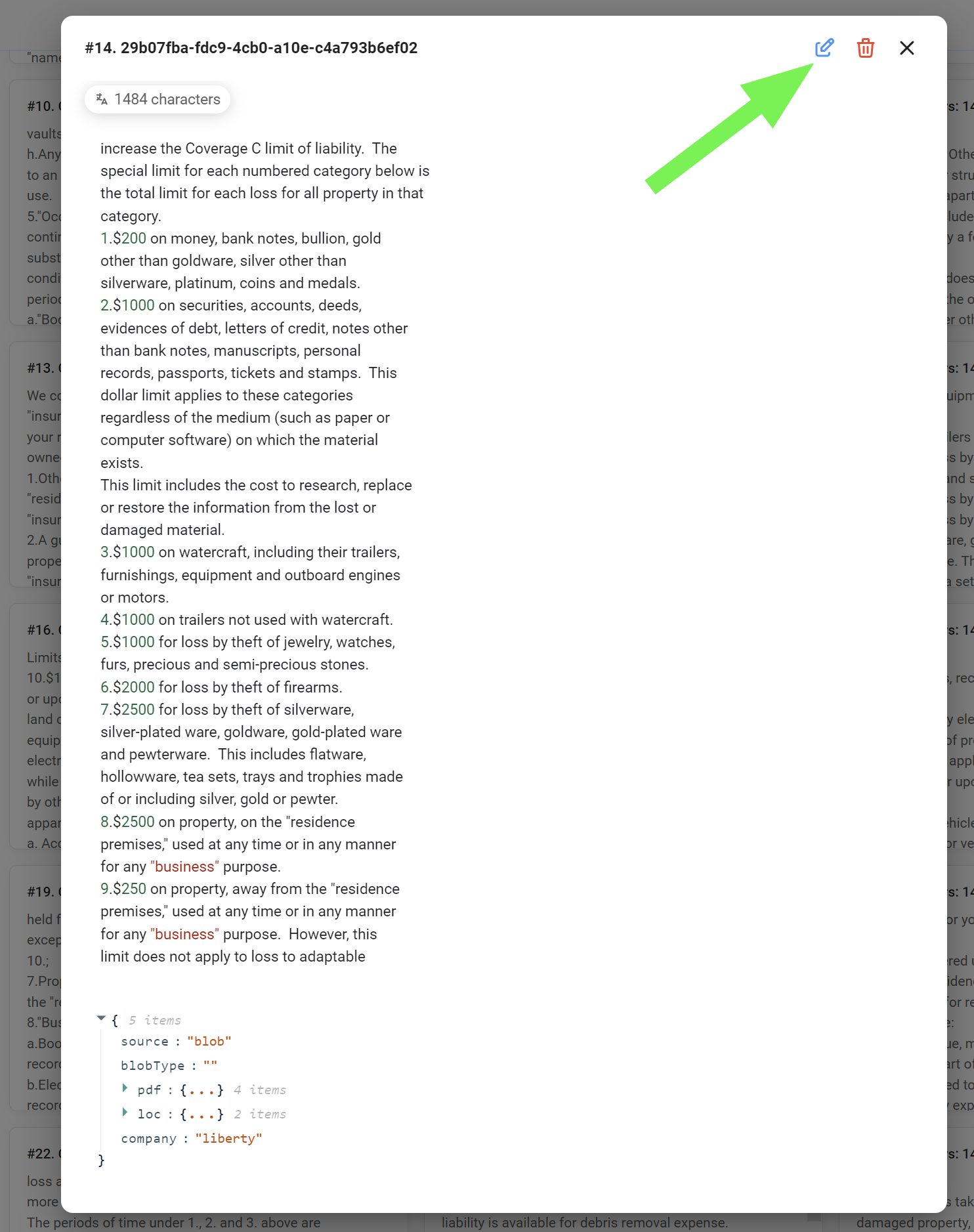
Note that once you have processed your data, you will be able to edit your chunks by deleting or adding data to them. This is beneficial if:
- You discover inaccuracies or inconsistencies in the original data: Editing chunks allows you to correct errors and ensure the information is accurate.
- You want to refine the content for better relevance: You can adjust chunks to emphasize specific information or remove irrelevant sections.
- You need to tailor chunks for specific queries: By editing chunks, you can make them more targeted to the types of questions you expect to receive.
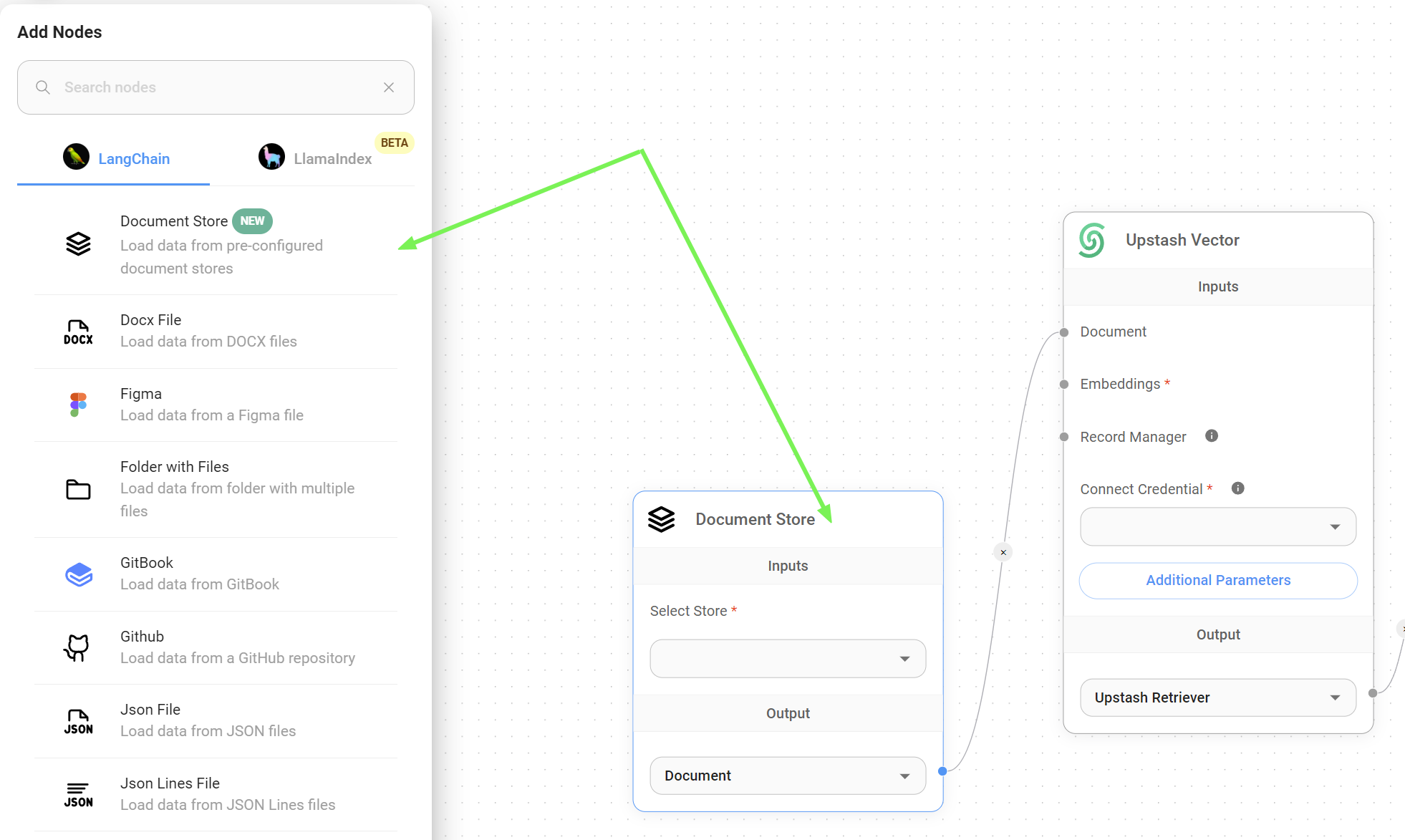
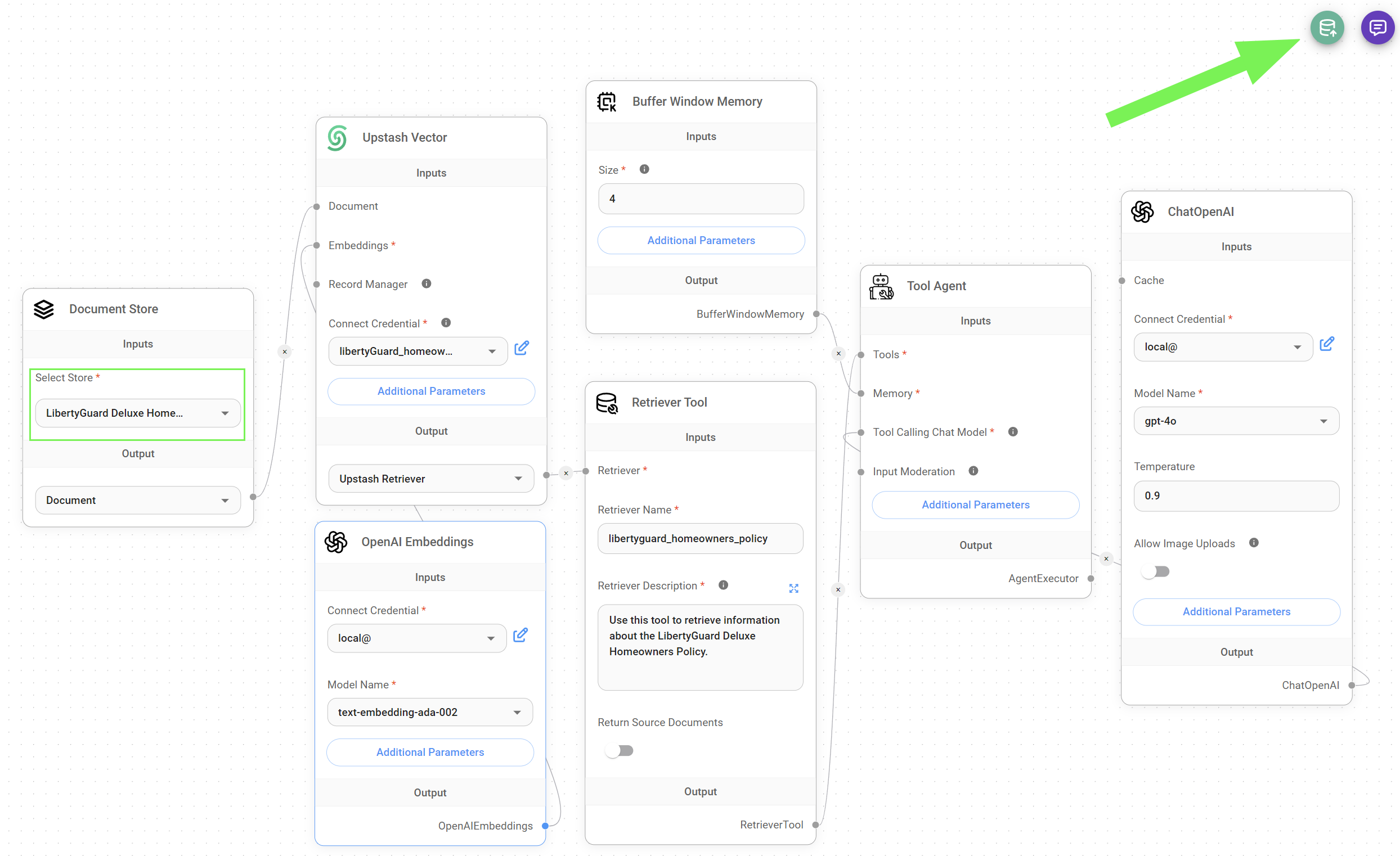
6. Add your Document Store node to your flow
- Now that our dataset is ready to be upserted, it's time to go to your RAG chatflow / agentflow and add the Document Store node under the LangChain > Document Loader section.
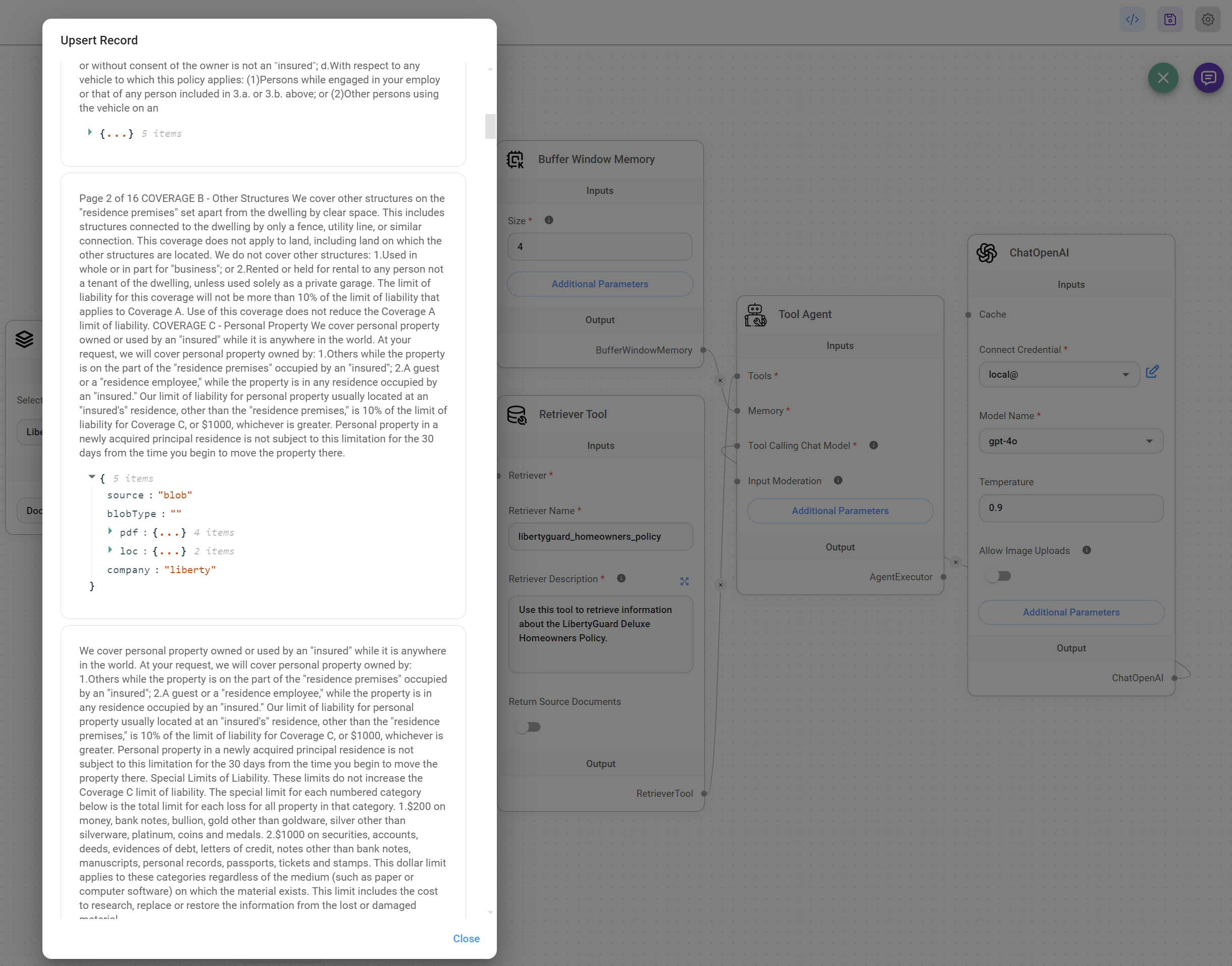
7. Upsert your data to a Vector Store
- Upsert your dataset to your Vector Store by clicking the green button in the right corner of your flow. We used the Upstash Vector Store in our implementation.
8. Test your RAG
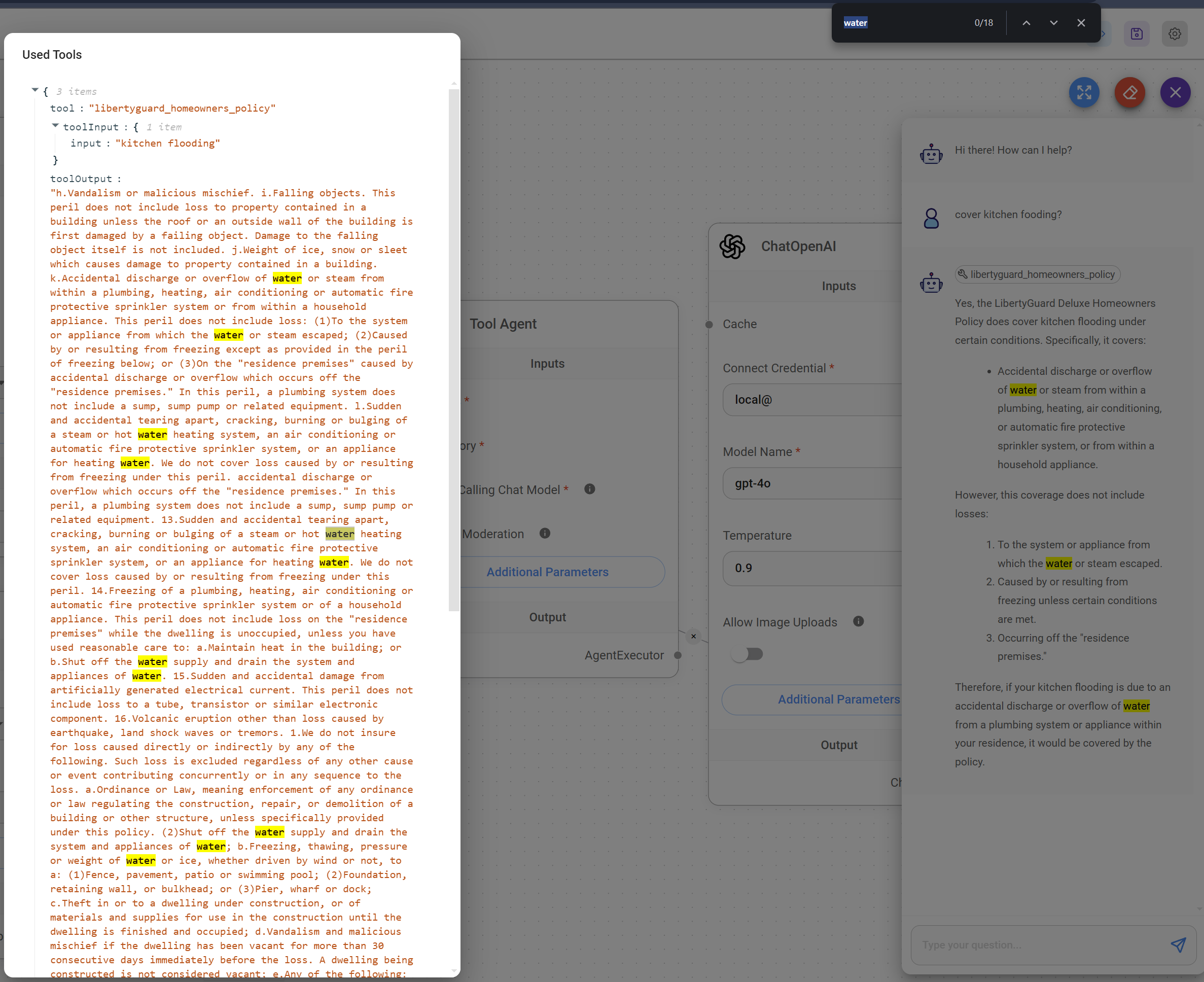
- Finally, our Retrieval-Augmented Generation (RAG) system is operational. It's noteworthy how the LLM effectively interprets the query and successfully leverages relevant information from the chunked data to construct a comprehensive response.
9. Summary
We started by creating a Document Store to organize the LibertyGuard Deluxe Homeowners Policy data. This data was then prepared by uploading, chunking, processing, and upserting it, making it ready for our RAG system.
Key benefits of using the Document Stores
- Organization and Management: The Document Store provides a centralized location for storing, managing, and preparing our data.
- Data Quality: The chunking process helps ensure that our data is structured in a way that facilitates accurate retrieval and analysis.
- Flexibility: The Document Store allows us to refine and adjust our data as needed, improving the accuracy and relevance of our RAG system.