VectorDB QA Chain
Overview
The VectorDB QA Chain is a powerful feature in AnswerAI that enables you to perform question-answering tasks using vector databases. This chain combines the capabilities of a language model with a vector store to provide accurate and contextual answers to your queries.
Key Benefits
- Efficient Information Retrieval: Quickly find relevant information from large datasets stored in vector databases.
- Contextual Understanding: Leverage the power of language models to interpret questions and generate coherent answers.
- Flexible Integration: Compatible with various vector stores and language models, allowing for customized setups.
How to Use
Follow these steps to set up and use the VectorDB QA Chain:
-
Select a Language Model: Choose a language model that will interpret your questions and generate answers.
-
Connect a Vector Store: Select a pre-configured vector store that contains your indexed data.
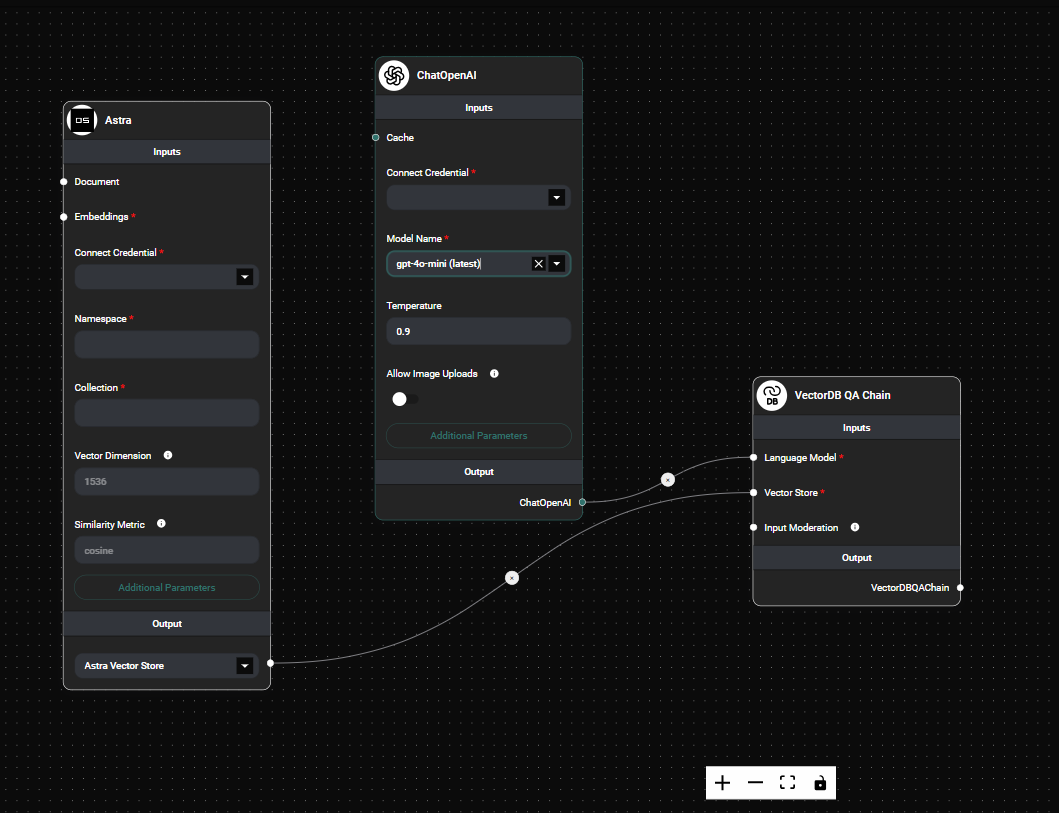
VectorDB QA Chain & Drop UI
-
Configure Input Moderation (Optional): Set up input moderation to filter out potentially harmful queries before they reach the language model.
-
Run Your Query: Enter your question, and the VectorDB QA Chain will process it, retrieve relevant information from the vector store, and generate an answer using the language model.
Tips and Best Practices
-
Optimize Vector Store: Ensure your vector store is well-indexed and contains relevant, high-quality data for the best results.
-
Phrase Questions Clearly: Frame your questions in a clear and specific manner to get more accurate answers.
-
Experiment with Different Models: Try different language models to find the one that works best for your specific use case and data.
-
Monitor Performance: Pay attention to response times and answer quality to optimize your chain configuration.
-
Use Input Moderation: Implement input moderation to ensure safe and appropriate use of the QA chain, especially in public-facing applications.
Troubleshooting
-
Irrelevant or Inaccurate Answers:
- Review the content in your vector store and ensure it's up-to-date and relevant.
- Try rephrasing your question or using more specific terms.
- Consider adjusting the
kvalue (number of retrieved documents) if available in your vector store configuration.
-
Slow Response Times:
- Check the performance of your vector store and consider optimizing its configuration.
- If using a complex language model, consider switching to a lighter version for faster processing.
-
Error Messages:
- If you encounter moderation-related errors, review your input moderation settings and ensure they're not overly restrictive.
- For other errors, check your language model and vector store connections.
-
Inconsistent Results:
- Ensure your vector store is not being updated while you're querying it, which could lead to inconsistent results.
- If using a random-based language model, consider setting a seed for reproducibility if needed.
Remember, the effectiveness of the VectorDB QA Chain depends on the quality of your vector store data and the capabilities of your chosen language model. Regularly update your vector store and stay informed about the latest advancements in language models to get the best results from your QA chain.